1. La classification de données
L’exemple typique qui permet d’illustrer la raison du succès du Machine Learning c’est la reconnaissance de l’écriture manuscrite.
Il s’agit belle et bien d’une tâche de classification de données puisque le but est de classer un « dessin » dans la bonne catégorie de lettres.
Imaginez que vous vouliez développer une IA capable de reconnaître les écritures manuscrites telles que présentées ci-dessous :

Dans cet exemple, la bonne interprétation (la bonne étiquette) se trouve en première ligne et les chiffres manuscrits à identifier sont en deuxième ligne. On remarquera que certaines étiquettes sont discutables. La deuxième par exemple pourrait très bien être 7, 4 ou 1.
Une première approche serait d’encoder des règles telles que :
- •
Si les pixels noirs ont principalement la forme d’une boucle, c’est un 0•
Si les pixels noirs ont principalement la forme de deux boucles collées, c’est un 8•
- Etc.
Ce qui correspondrait aux systèmes experts que nous avons abordés dans le premier module.
Seulement cette méthode ne serait pas satisfaisante, car les écritures manuscrites sont irrégulières, ce qui veut littéralement dire qu’elles ne correspondent pas strictement à des règles.
Dans notre exemple,
prenez le 7e chiffre en partant de la droite.

La règle « Si les pixels noirs ont principalement la forme de deux boucles collées, c’est un 8 » ne permettrait pas de reconnaitre ce dessin, car les boucles sont mal dessinées et décalées l’une par rapport à l’autre.
Pour parvenir à mieux identifier ces chiffres manuscrits, il faut une autre approche.
Lorsque l’on sort des domaines gouvernés par des règles simples, notre meilleur ami c’est la statistique.
L’idée désormais n’est plus de déterminer quelles sont les règles qui définissent l’écriture manuscrite – puisqu’il y a trop d’éléments perturbateurs – mais plutôt de se demander dans ce cas-ci : « Quelle est la probabilité que ce soit un 1,2,3, etc. ? »
On pourrait résumer ce principe par : « Celui qui a la plus grande probabilité gagne. »
En faisant appel à des règles statistiques, les experts de l’IA ont mis en place des machines capables d’analyser des données, de regrouper les données semblables et d’en isoler des tendances. Ainsi, les machines sont devenues capables de dire :
« Dans toutes les informations auxquelles j’ai eu accès, tout ce qui ressemblait à deux cercles collés correspondait à des 8. Ici, je vois quelque chose de semblable, alors la probabilité que ce soit un 8 est suffisante pour supposer que c’est un 8 ».
Et c’est ce travail de classification en amont qu’on appelle apprentissage.
En résumé, l’IA est capable de classifier certaines données selon leur ressemblance avec d’autres données auxquelles elle a déjà eu accès.
2. Préparation des données
Bien que le Machine Learning soit capable de créer lui-même son algorithme pour obtenir des résultats de qualité, il est généralement nécessaire de traiter les données en amont. Sans entrer dans les détails techniques, retenons que les différentes solutions de Machine Learning ont leurs propres conditions de validités et pour les utiliser il faut qu’un expert en statistique et data analyse adapte les données à ces conditions.

Schéma représentant les étapes du processus de Machine Learning.
Le schéma se lit de gauche à droite : à partir de données fournies (”entrées”), l’IA définit des caractéristiques pour les regrouper et les identifier. Ces caractéristiques validées par un expert ou data analyste, serviront à l’IA pour son apprentissage et le traitement de ces données, voire de données complémentaires ultérieures.
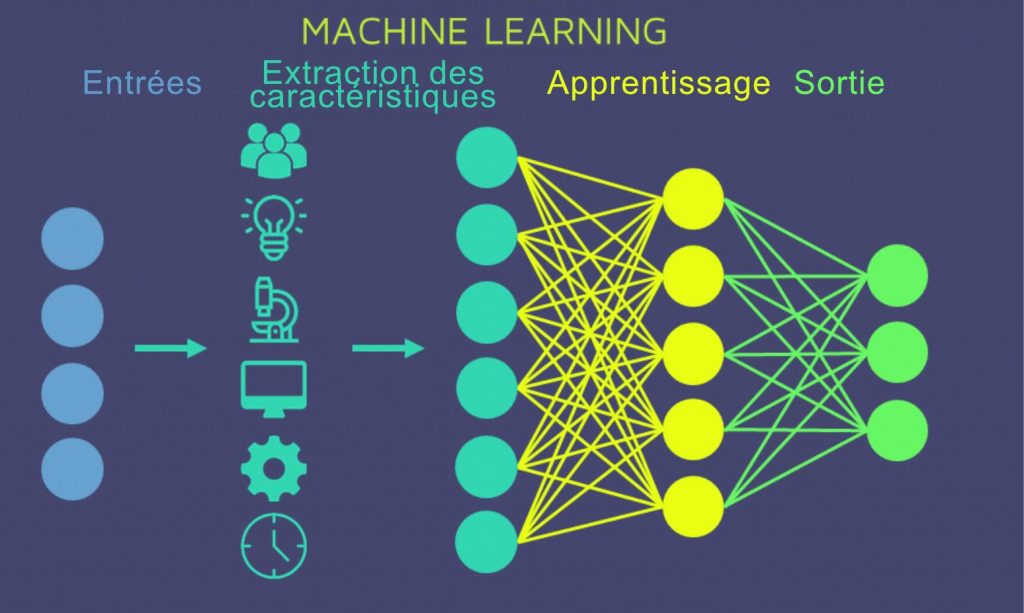
Schéma représentant les étapes du processus de Machine Learning.
Le schéma se lit de gauche à droite : à partir de données fournies (”entrées”), l’IA définit des caractéristiques pour les regrouper et les identifier. Ces caractéristiques validées par un expert ou data analyste, serviront à l’IA pour son apprentissage et le traitement de ces données, voire de données complémentaires ultérieures.
3. Les quatre types d’apprentissages automatiques
Depuis le début de ce cours, nous répétons que l’IA est capable d’apprendre par elle-même et de s’améliorer par l’expérience. Mais concrètement, comment ça marche ?
Vous allez découvrir 4 techniques d’apprentissages automatiques utilisées pour entrainer l’IA.
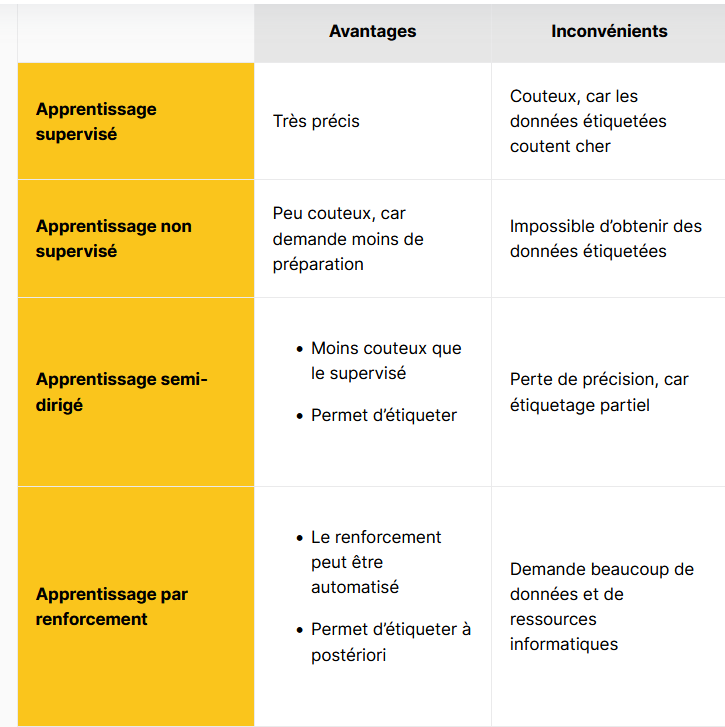
A-Apprentissage supervisé
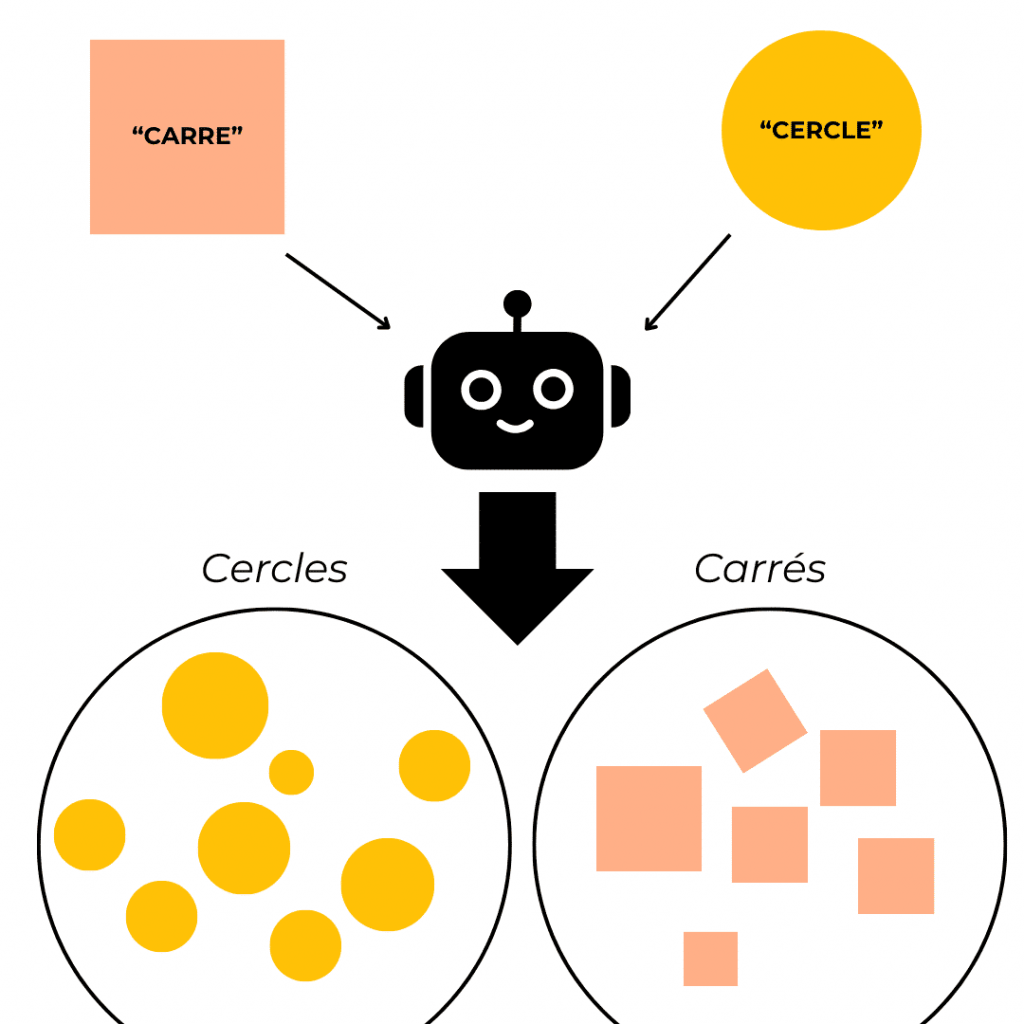
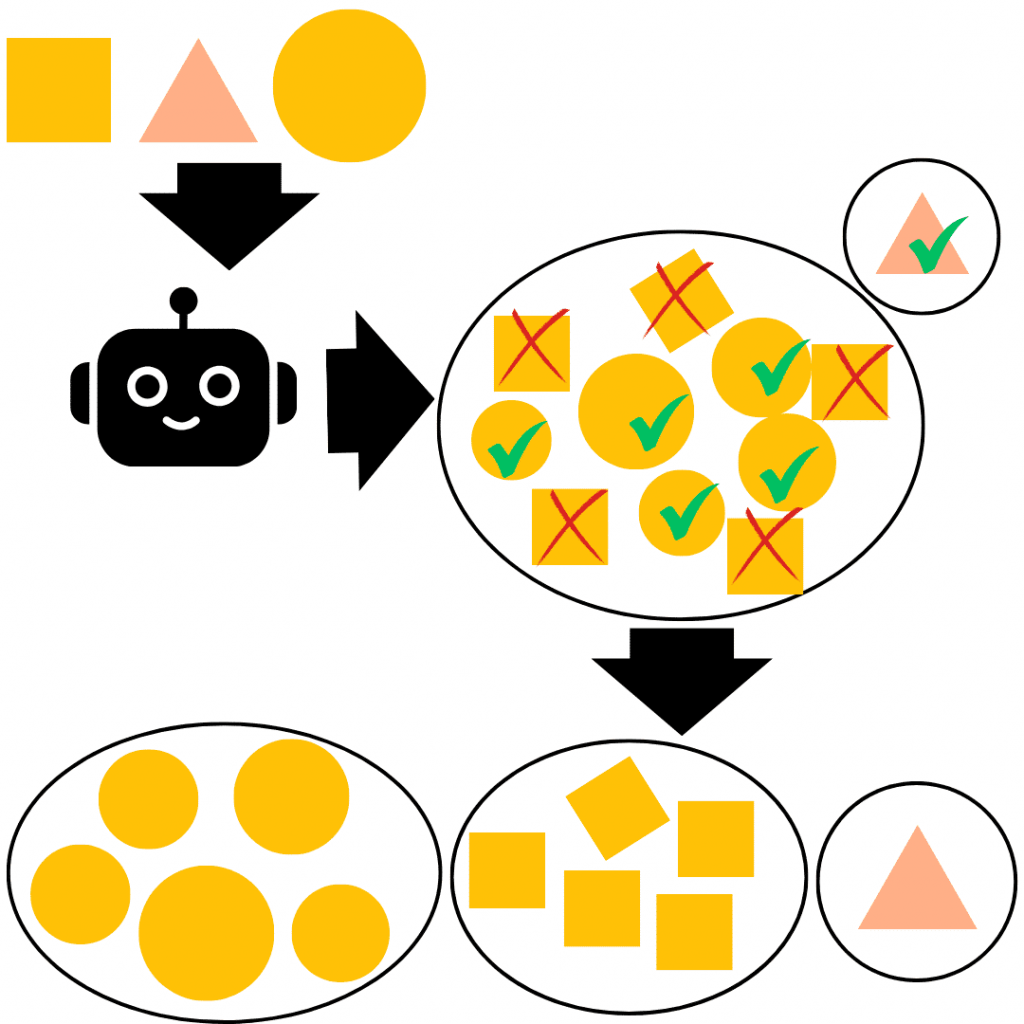
Cet apprentissage consiste à fournir à l’IA une certaine quantité de données déjà étiquetées, c’est-à-dire des données dont on connaît déjà le résultat pour ensuite identifier les caractéristiques communes aux éléments qui ont la même étiquette.
Dans notre exemple, l’IA se dirait : « Toutes les écritures étiquetées 8 ont des pixels qui forment deux cercles collés. Donc tout ce qui ressemble à deux cercles collés sont des 8 ».
En apprentissage supervisé, la supervision vient du fait que quelqu’un doit fournir des données dont on connaît déjà le résultat correct.
Il faut savoir que des données étiquetées, ce n’est pas si simple à obtenir. Souvent, cela coute cher, et il faut soit avoir déjà une base de données et donc dépenser de l’argent en récolte, stockage et traitement des données, soit acheter ces données.
B-Apprentissage non supervisé
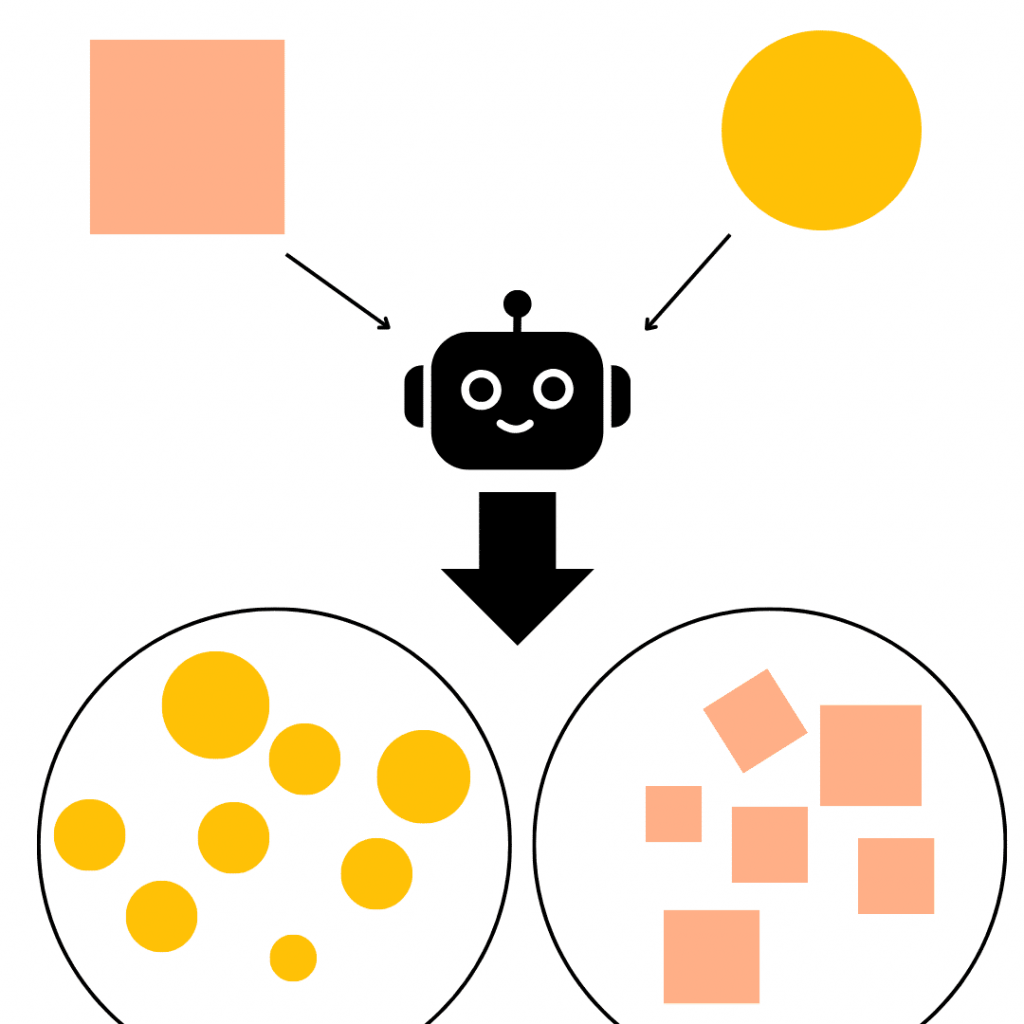
À l’inverse de l’apprentissage supervisé, dans ce cas il n’y a pas de bonne réponse, il n’y a pas d’étiquette. Le rôle de l’IA sera alors de rassembler les données selon des caractéristiques communes.
Dans notre exemple, on fournirait seulement la seconde ligne de données et l’IA tâcherait de classer ensemble toutes les formes composées de 2 cercles de pixels collés.
Dans ce cas, si on lui demande d’identifier une suite de chiffres, il ne pourra pas dire que celui-ci est un 8. Mais il dira celui-ci ressemble fort à tous ceux-là.
C-Apprentissage semi-dirigé
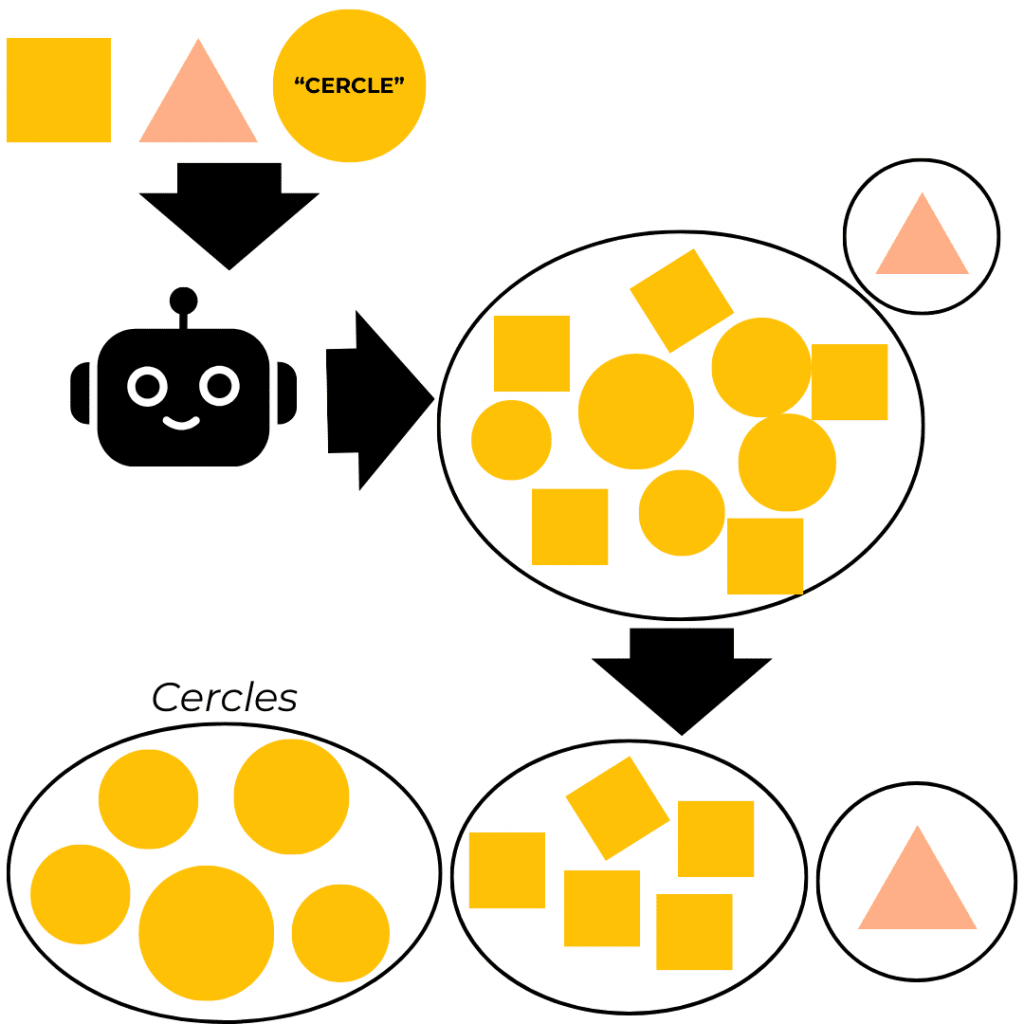
Il est également possible de combiner les deux approches en fournissant des données étiquetées et des données non étiquetées. L’IA va alors, dans un premier temps, classifier les données semblables sans prendre en compte les étiquettes.
Si, au sein d’une même catégorie, se retrouvent des données étiquetées de la même manière, alors il comprendra comment associer les données aux bonnes étiquettes.
4-Apprentissage par renforcement
Cette méthode consiste à « éduquer » l’IA un peu comme un enfant. On lui fournit des données non étiquetées. Si elle les catégorise bien, alors on la récompense (renforcement positif) et si elle se trompe, on la réprimande (renforcement négatif) et ainsi de suite, jusqu’à ce qu’elle arrête de se tromper.
Il est également possible d’étiqueter les données a posteriori.
Toujours dans l’exemple de la reconnaissance d’image, on peut laisser l’IA clusterer (catégoriser) les données pour ensuite donner un nom à ces catégories. Et vous l’avez probablement tous déjà fait sans le savoir.